
AniTalker – 通过音频和人像生产动画脸部表情视频
简介
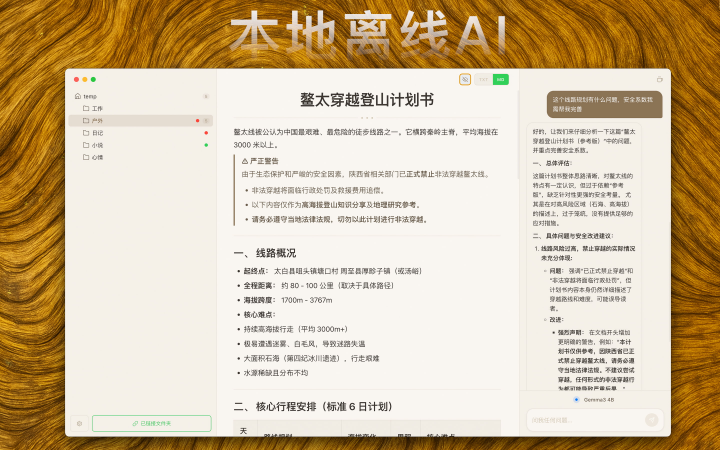
上海交大开源的一个创新的框架,对口型说话视频生成框架。旨在从单一静态人像和输入音频生成逼真的说话视频,通过身份解耦面部动作编码来实现。
与现有主要关注口型同步模型不同,AniTalker 采用一种通用运动表示方式,能够捕捉丰富的面部动态,包括微妙表情和头部运动。
演示
特色
- 自监督学习:通过重建目标视频帧和使用度量学习、互信息解耦,学习到的面部动作表示既健壮又具有多样性。
- 通用运动表示:AniTalker 的运动表示不包含特定身份细节,减少了对标记数据的需求。
- 扩散模型与方差适配器:结合使用这些技术,可以生成多样化且可控的面部动画。
网址
演示:https://x-lance.github.io/AniTalker/
开源:https://github.com/X-LANCE/AniTalker
论文:https://arxiv.org/abs/2405.03121
THE END
0
二维码
打赏
海报


AniTalker – 通过音频和人像生产动画脸部表情视频
上海交大开源的一个创新的框架,对口型说话视频生成框架。旨在从单一静态人像和输入音频生成逼真的说话视频,通过身份解耦面部动作编码来实现。与现有主要关注口型同步模型不同,AniTalker 采用一种通用运动表示方式,能够捕捉丰富的面部动态,包括微妙表情和头部运动。




共有 0 条评论